 |
 |
 |
 | Model fitting by least squares |  |
![[pdf]](icons/pdf.png) |
Next: Normal equations
Up: MULTIVARIATE LEAST SQUARES
Previous: MULTIVARIATE LEAST SQUARES
In engineering uses,
a vector has three scalar components that
correspond to the three dimensions of the space in which we live.
In least-squares data analysis, a vector is a one-dimensional array
that can contain many different things.
Such an array is an ``abstract vector.''
For example, in earthquake studies,
the vector might contain the time
an earthquake began, as well as its latitude, longitude, and depth.
Alternatively, the abstract vector
might contain as many components as there are seismometers,
and each component might be the arrival time of an earthquake wave.
Used in signal analysis,
the vector might contain the values of a signal
at successive instants in time or,
alternatively, a collection of signals.
These signals might be ``multiplexed'' (interlaced)
or ``demultiplexed'' (all of each signal preceding the next).
When used in image analysis,
the one-dimensional array might contain an image,
which is an array of signals.
Vectors, including abstract vectors,
are usually denoted by boldface letters such as  and
and  .
Like physical vectors,
abstract vectors are orthogonal
if a dot product vanishes:
.
Like physical vectors,
abstract vectors are orthogonal
if a dot product vanishes:
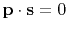 .
Orthogonal vectors are well known in physical space;
we also encounter orthogonal vectors in abstract vector space.
.
Orthogonal vectors are well known in physical space;
we also encounter orthogonal vectors in abstract vector space.
We consider first a hypothetical application
with one data vector  and two
fitting vectors
and two
fitting vectors  and
and  .
Each fitting vector is also known as a ``regressor.''
Our first task is to approximate the data vector
by a scaled combination of the two regressor vectors.
The scale factors
.
Each fitting vector is also known as a ``regressor.''
Our first task is to approximate the data vector
by a scaled combination of the two regressor vectors.
The scale factors  and
and  should be chosen so the model matches the data; i.e.,
should be chosen so the model matches the data; i.e.,
 |
(21) |
Notice that we could take the partial derivative
of the data in (21) with respect to an unknown,
say ,
and the result is the regressor .
The partial derivative of all modeled data  with respect to any particular model parameter
with respect to any particular model parameter  gives a regressor.
gives a regressor.
A regressor is a column in the
matrix of partial-derivatives,
 . .
|
The fitting goal (21) is often expressed in the more compact
mathematical matrix notation
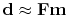 ,
but in our derivation here,
we keep track of each component explicitly
and use mathematical matrix notation to summarize the final result.
Fitting the observed data
,
but in our derivation here,
we keep track of each component explicitly
and use mathematical matrix notation to summarize the final result.
Fitting the observed data
 to its two theoretical parts
to its two theoretical parts
 and
and  can be expressed
as minimizing the length of the residual vector
can be expressed
as minimizing the length of the residual vector  , where:
, where:
We use a dot product to construct a sum of squares (also called a ``quadratic form'')
of the components of the residual vector:
To find the gradient of the quadratic form  ,
you might be tempted to expand out the dot product into all nine terms
and then differentiate.
It is less cluttered, however, to remember the product rule, that:
,
you might be tempted to expand out the dot product into all nine terms
and then differentiate.
It is less cluttered, however, to remember the product rule, that:
 |
(26) |
Thus, the gradient of is defined by its two components:
 |
(27) |
Setting these derivatives to zero and using
 etc.,
we get
etc.,
we get
 |
(28) |
We can use these two equations to solve for
the two unknowns and .
Writing this expression in matrix notation, we have:
![\begin{displaymath}
\left[
\begin{array}{c}
({\bf f}_1 \cdot {\bf d}) \\
({\...
...\; \left[
\begin{array}{c}
m_1 \\
m_2 \end{array} \right]
\end{displaymath}](img138.png) |
(29) |
It is customary to use matrix notation without dot products.
For matrix notation
we need some additional definitions.
To clarify these definitions,
we inspect vectors
 ,
,  , and of three components.
Thus,
, and of three components.
Thus,
![\begin{displaymath}
\bold F \eq [ {\bf f}_1 \quad {\bf f}_2 ] \eq
\left[
\begi...
...\\
f_{21} & f_{22} \\
f_{31} & f_{32} \end{array} \right]
\end{displaymath}](img141.png) |
(30) |
Likewise, the transposed matrix  is defined by:
is defined by:
![\begin{displaymath}
\bold F\T \eq
\left[
\begin{array}{ccc}
f_{11} & f_{21} & f_{31} \\
f_{12} & f_{22} & f_{32} \end{array} \right]
\end{displaymath}](img143.png) |
(31) |
Using this matrix  , there is a simple expression
for the gradient calculated in equation (27).
It is used in nearly every example in this book.
, there is a simple expression
for the gradient calculated in equation (27).
It is used in nearly every example in this book.
![\begin{displaymath}
\bold g \eq
\left[
\begin{array}{c}
\frac{\partial Q}{\part...
...
r_1 \\
r_2 \\
r_3
\end{array}\right]
\eq
{\bf F}\T\,{\bf r}
\end{displaymath}](img145.png) |
(32) |
In words this expression says, the gradient is found by putting the
residual into the adjoint operator
 . Notice, the gradient
. Notice, the gradient  has the same number of
components as the unknown solution
has the same number of
components as the unknown solution 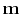 , so we can think of the
gradient as a
, so we can think of the
gradient as a
 , something we could add to
getting
, something we could add to
getting
 . Later, we see how much of
we want to add to . We reach the best
solution when we find the gradient
. Later, we see how much of
we want to add to . We reach the best
solution when we find the gradient
 vanishes, which
happens as equation (32) says, when the residual is orthogonal to all the fitting functions (all the rows in the matrix
vanishes, which
happens as equation (32) says, when the residual is orthogonal to all the fitting functions (all the rows in the matrix  , the columns in
, the columns in 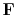 , are perpendicular to
, are perpendicular to  ).
).
The matrix in equation (29)
contains dot products.
Matrix multiplication is an abstract way of representing the dot products:
![\begin{displaymath}
\left[
\begin{array}{ccc}
({\bf f}_1 \cdot {\bf f}_1) & ({...
...\\
f_{21} & f_{22} \\
f_{31} & f_{32} \end{array} \right]
\end{displaymath}](img155.png) |
(33) |
Thus, equation (29) without dot products is:
![\begin{displaymath}
\left[
\begin{array}{ccc}
f_{11} & f_{21} & f_{31} \\
f_...
...
\left[
\begin{array}{ccc}
m_1 \\
m_2 \end{array} \right]
\end{displaymath}](img156.png) |
(34) |
which has the matrix abbreviation:
 |
(35) |
Equation
(35)
is the classic result of least-squares
fitting of data to a collection of regressors.
Obviously, the same matrix form applies when there are more than
two regressors and each vector has more than three components.
Equation
(35)
leads to an analytic solution for  using an inverse matrix.
To solve formally for the unknown ,
we premultiply by the inverse matrix
using an inverse matrix.
To solve formally for the unknown ,
we premultiply by the inverse matrix
 :
:
 |
(36) |
The central result of
least-squares
theory is
 .
We see it everywhere. .
We see it everywhere.
|
Let us examine all the second derivatives of defined by equation (25).
Any multiplying does not survive the second derivative, therefore, the terms we are left with are:
 |
(37) |
After taking the second derivative, we can organize all these terms in a matrix:
![\begin{displaymath}
\frac{\partial^2 Q}{\partial m_i\partial m_j} \eq
\left[
\...
...{\bf f}_1) & ({\bf f}_2 \cdot {\bf f}_2)
\end{array} \right]
\end{displaymath}](img163.png) |
(38) |
Comparing equation (38) to equation (33) we conclude
that
 is a matrix of second derivatives.
This matrix is also known as the
Hessian.
It often plays an important role in small problems.
is a matrix of second derivatives.
This matrix is also known as the
Hessian.
It often plays an important role in small problems.
Larger problems tend to have insufficient computer memory for the Hessian matrix,
because it is the size of model space squared.
Where model space is a multidimensional Earth image,
we have a large number of values even before squaring that number.
Therefore, this book rarely works with the Hessian,
working instead with gradients.
Rearrange parentheses representing (34).
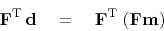 |
(39) |
Equation
(35)
led to the ``analytic'' solution (36).
In a later section on conjugate directions,
we see that equation
(39)
expresses better than
equation
(36)
the philosophy of iterative methods.
Notice how equation
(39)
invites us to cancel the matrix
from each side.
We cannot do that of course, because
is not a number, nor is it a square matrix with an inverse.
If you really want to cancel the matrix , you may,
but the equation is then only an approximation
that restates our original goal (21):
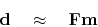 |
(40) |
Speedy problem solvers might
ignore the mathematics covering the previous page,
study their application until they
are able to write the statement of goals
(40) = (21),
premultiply by ,
replace  by =,
getting (35),
and take
(35)
to a simultaneous equation-solving program to get .
by =,
getting (35),
and take
(35)
to a simultaneous equation-solving program to get .
What I call ``fitting goals'' are called
``regressions'' by statisticians.
In common language the word regression means
to ``trend toward a more primitive perfect state,''
which vaguely resembles reducing the size of (energy in)
the residual
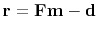 .
Formally,
the fitting is often written as:
.
Formally,
the fitting is often written as:
 |
(41) |
The notation with two pairs of vertical lines
looks like double absolute value,
but we can understand it as a reminder to square and sum all the components.
This formal notation is more explicit
about what is constant and what is variable during the fitting.
|
|
|
|
| Model fitting by least squares | |
|
Next: Normal equations
Up: MULTIVARIATE LEAST SQUARES
Previous: MULTIVARIATE LEAST SQUARES
2014-12-01