In comparing two datasets, the purpose is to estimate a smoothly varying warping function, 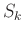 , required to align one dataset,
, required to align one dataset,  , to a reference dataset,
, to a reference dataset,  ,
,
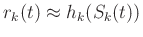 |
(19) |
We can represent the warping function with the shifts, 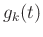 , as follows:
, as follows:
 |
(20) |
where the 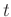 denotes the original independent axis and are the shifts required to match the datasets as defined in Equation A-1. The correlation coefficient can be used to quantify the quality of the match between datasets (Hampson-Russell, 1999). The LSIM method begins with the observation that the correlation coefficient (
denotes the original independent axis and are the shifts required to match the datasets as defined in Equation A-1. The correlation coefficient can be used to quantify the quality of the match between datasets (Hampson-Russell, 1999). The LSIM method begins with the observation that the correlation coefficient ( ) only provides one number to describe the datasets; however, we am interested in understanding the local changes in the datasets' similarity. Therefore, the LSIM method computes local similarity
) only provides one number to describe the datasets; however, we am interested in understanding the local changes in the datasets' similarity. Therefore, the LSIM method computes local similarity 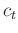 , which is a function of time, . The square of can be split into a product of two factors (Fomel, 2007a):
, which is a function of time, . The square of can be split into a product of two factors (Fomel, 2007a):
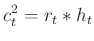 |
(21) |
where  and
and  are the solutions to the following regularized least-squares problems, respectively
are the solutions to the following regularized least-squares problems, respectively
The regularization operator,  , is implemented using shaping regularization (Fomel, 2007b) and designed to enforce smoothness. To estimate the solution, LSIM is calculated for a series of shifts. The results of this calculation are accumulated and displayed on a `similarity scan.'
, is implemented using shaping regularization (Fomel, 2007b) and designed to enforce smoothness. To estimate the solution, LSIM is calculated for a series of shifts. The results of this calculation are accumulated and displayed on a `similarity scan.'
2019-05-07
![\begin{equation*}\begin{aligned}
\min_{r_t}(\sum_{t}(a_t - r_tb_t)^2 + R[r_t]) \...
...n_{h_t}(\sum_{t}(b_t - h_ta_t)^2 + R[h_t]) \\ [3pt]
\end{aligned}\end{equation*}](img66.png)